



> ,kloc,0 > ,acap,0.22927988981346761332 > ,data,0.2334438373917348819 > ,time,0.25423355037952316549 > ,plex,0.26866055225810964169 > ,stor,0.27441589382858594393 > ,pmat,0.3093114132807298633 > ,cplx,0.34470954768369121979 > ,apex,0.35198812495229314656 > ,pcap,0.36553252022821636213 > ,rely,0.40329996377433946497 > ,ltex,0.46603801062070232542 > ,pvol,0.56369464132541236001 > ,sced,0.58780717952192207409 > ,tool,0.82277351898917538975 > ,docu,1 > ,flex,1 > ,pcon,1 > ,prec,1 > ,resl,1 > ,ruse,1 > ,site,1 > ,team,1coc81
> ,tool,0 > ,acap,1 > ,aexp,1 > ,cplx,1 > ,data,1 > ,dev_mode,1 > ,lexp,1 > ,loc,1 > ,modp,1 > ,pcap,1 > ,project_id,1 > ,rely,1 > ,sced,1 > ,stor,1 > ,time,1 > ,turn,1 > ,vexp,1 > ,virt,1desharnais
>> ,YearEnd,0 >> ,Adjustment,1 >> ,Entities,1 >> ,Langage,1 >> ,Length,1 >> ,ManagerExp,1 >> ,PointsAjust,1 >> ,PointsNonAdjust,1 >> ,Project,1 >> ,TeamExp,1 >> ,Transactions,1finnish
>> ,prod,0 >> ,at,1 >> ,co,1 >> ,FP,1 >> ,hw,1 nasa93n
>> ,prec,0 >> ,flex,0.11243402160650950439 >> ,docu,0.33052121547798030132 >> ,resl,0.40212091296737206836 >> ,apex,0.46229399349528710328 >> ,data,0.46229399349528710328 >> ,acap,0.61482323785435888386 >> ,pvol,0.61482323785435888386 >> ,sced,0.61482323785435888386 >> ,stor,0.61482323785435888386 >> ,cplx,0.70398054754829086921 >> ,kloc,0.78682242656022605143 >> ,ltex,0.78682242656022605143 >> ,pcap,0.78682242656022605143 >> ,pmat,0.78682242656022605143 >> ,rely,0.78682242656022605143 >> ,ruse,0.78682242656022605143 >> ,team,0.78682242656022605143 >> ,time,0.78682242656022605143 >> ,tool,0.78682242656022605143 >> ,plex,0.87700247550119436735 >> ,site,0.87700247550119436735 >> ,pcon,1 china
>> ,Duration,0 >> ,Resource,0.18076822524622718213 >> ,Enquiry,0.70229300937753547096 >> ,Added,0.70418156239280693676 >> ,NPDR_AFP,0.71748509491228684709 >> ,AFP,0.84023872986505276916 >> ,N_effort,0.84023872986505276916 >> ,Interface,0.85325277904975838084 >> ,File,0.9226111617867434056 >> ,Input,0.94562919153491631352 >> ,Output,0.96948001254205484756 >> ,Changed,0.98391349972332420304 >> ,Deleted,1 >> ,Dev.Type,1 >> ,ID,1 >> ,NPDU_UFP,1 >> ,PDR_AFP,1 >> ,PDR_UFP,1 miyazaki94
>> ,KLOC,0 >> ,FORM,0.40638957366031353002 >> ,ESCRN,0.43471405099857385324 >> ,EFILE,0.63742030743007560556 >> ,FILE,0.74270091796517645477 >> ,EFORM,0.89605538051121036425 >> ,SCRN,1
#data sets cutoff a ignore 0 25 50 75 100 ---------------- ------ - ------------- --- --- ---- ---- ---- data/nasa93.arff, 0.25, 5, 1, , , 10, 0, |, 0, 0.6, 0.81, 0.91, 9.99 data/nasa93.arff, 0.33, 7, 1, , , 10, 0, |, 0, 0.51, 0.77, 0.89, 7.33 data/nasa93.arff, 0.5, 11, 1, , , 10, 0, |, 0, 0.35, 0.69, 0.85, 33.08 data/nasa93.arff, 0.66, 15, 1, , , 10, 0, |, 0, 0.37, 0.61, 0.84, 7 data/nasa93.arff, 0.75, 23, 1, , , 10, 0, |, 0, 0.4, 0.63, 0.9, 12.5 data/nasa93.arff, 1, 23, 1, , , 10, 0, |, 0, 0.42, 0.63, 0.83, 7.33
data/desharnais.arff, 0.001, 1, 1, , , 10, 0, |, 0, 0.34, 0.46, 0.65, 5.92 data/desharnais.arff, 0.25, 11, 1, , , 10, 0, |, 0, 0.22, 0.37, 0.56, 3.87 data/desharnais.arff, 0.33, 11, 1, , , 10, 0, |, 0, 0.25, 0.37, 0.56, 3.87 data/desharnais.arff, 0.5, 11, 1, , , 10, 0, |, 0, 0.25, 0.37, 0.56, 3.87 data/desharnais.arff, 0.66, 11, 1, , , 10, 0, |, 0, 0.25, 0.37, 0.56, 3.87 data/desharnais.arff, 0.75, 10, 1, , , 10, 0, |, 0, 0.27, 0.48, 0.62, 4.18 data/desharnais.arff, 1, 11, 1, , , 10, 0, |, 0, 0.25, 0.37, 0.56, 3.87
data/finnish.arff, 0.001, 1, 1, , , 10, 0, |, 0.02, 0.48, 0.71, 0.81, 5.23 data/finnish.arff, 0.25, 1, 1, , , 10, 0, |, 0.05, 0.59, 0.79, 0.85, 4.77 data/finnish.arff, 0.33, 1, 1, , , 10, 0, |, 0.01, 0.58, 0.72, 0.84, 4.9 data/finnish.arff, 0.5, 5, 1, , , 10, 0, |, 0.09, 0.61, 0.76, 0.85, 9.5 data/finnish.arff, 0.66, 5, 1, , , 10, 0, |, 0.09, 0.61, 0.76, 0.85, 9.5 data/finnish.arff, 0.75, 5, 1, , , 10, 0, |, 0.09, 0.61, 0.76, 0.85, 9.5 data/finnish.arff, 1, 5, 1, , , 10, 0, |, 0.09, 0.61, 0.76, 0.85, 9.5
data/coc81.arff, 0.001, , 1, , , 10, 0, |, 0.07, 0.63, 0.82, 0.98, 15.92 data/coc81.arff, 0.25, 18, 1, , , 10, 0, |, 0.04, 0.76, 0.93, 1, 15.25 data/coc81.arff, 0.33, 18, 1, , , 10, 0, |, 0, 0.6, 0.77, 0.93, 18.58 data/coc81.arff, 0.5, 18, 1, , , 10, 0, |, 0.04, 0.63, 0.86, 0.98, 30.5 data/coc81.arff, 0.66, 18, 1, , , 10, 0, |, 0.04, 0.62, 0.89, 0.99, 27.75 data/coc81.arff, 0.75, 18, 1, , , 10, 0, |, 0, 0.49, 0.85, 0.98, 15.92 data/coc81.arff, 1, 18, 1, , , 10, 0, |, 0, 0.63, 0.84, 0.98, 17.47
data/coc81.arff, 0.001, 1, 1, , , 10, 0, |, 0.04, 0.69, 0.9, 0.98, 14.57 data/coc81.arff, 0.25, 18, 1, , , 10, 0, |, 0, 0.47, 0.82, 0.96, 27.75 data/coc81.arff, 0.33, 18, 1, , , 10, 0, |, 0.01, 0.66, 0.86, 0.98, 15.92 data/coc81.arff, 0.5, 18, 1, , , 10, 0, |, 0.04, 0.58, 0.86, 0.98, 16.96 data/coc81.arff, 0.66, 18, 1, , , 10, 0, |, 0.05, 0.62, 0.94, 1.45, 25.86 data/coc81.arff, 0.75, 18, 1, , , 10, 0, |, 0, 0.62, 0.91, 0.96, 15.92 data/coc81.arff, 1, 18, 1, , , 10, 0, |, 0.06, 0.69, 0.88, 0.99, 15.92
data/miyazaki94.arff, 0.001, 1, 1, , , 10, 0, |, 0, 0.24, 0.45, 0.7, 6.02 data/miyazaki94.arff, 0.25, 1, 1, , , 10, 0, |, 0, 0.2, 0.46, 0.76, 14.25 data/miyazaki94.arff, 0.33, 2, 1, , , 10, 0, |, 0.03, 0.39, 0.61, 0.72, 14.25 data/miyazaki94.arff, 0.5, 3, 1, , , 10, 0, |, 0.01, 0.24, 0.43, 0.63, 4.36 data/miyazaki94.arff, 0.66, 4, 1, , , 10, 0, |, 0, 0.4, 0.61, 0.79, 3.79 data/miyazaki94.arff, 0.75, 5, 1, , , 10, 0, |, 0.02, 0.31, 0.45, 0.72, 3.57 data/miyazaki94.arff, 1, 7, 1, , , 10, 0, |, 0, 0.2, 0.63, 0.78, 5.35
data/china.arff, 0.001, 1, 1, , , 10, 0, |, 0, 0.5, 0.76, 0.94, 93.48 data/china.arff, 0.25, 5, 1, , , 10, 0, |, 0, 0.14, 0.27, 0.45, 14.67 data/china.arff, 0.33, 5, 1, , , 10, 0, |, 0, 0.44, 0.66, 0.83, 46.84 data/china.arff, 0.5, 9, 1, , , 10, 0, |, 0, 0.21, 0.37, 0.58, 8.46 data/china.arff, 0.66, 13, 1, , , 10, 0, |, 0, 0.24, 0.38, 0.59, 13.63 data/china.arff, 0.75, 18, 1, , , 10, 0, |, 0, 0.38, 0.58, 0.76, 12.08 data/china.arff, 1, 18, 1, , , 10, 0, |, 0, 0.37, 0.57, 0.75, 19.35


https://bugcatcher.stca.herts.ac.uk/slr2011/
A Systematic Review of Fault Prediction Performance in Software Engineering
http://www.computer.org/portal/web/csdl/abs/trans/ts/5555/01/tts555501toc.htm
http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6035727&tag=1
given N arrays of performance results p .... of treatments 1,2,3...
with means m[1],m[2], etc
with stand devs of s[1], s[2], etc then ...
for i in N
for j in N
boring[i,j] = (abs(m[i] - m[i])/s <= 0.3) #cohen
samples=1000
N*samples timesRepeat: {
i = any index 1..N
j= any index 1..N
if (boring[i,j] continue
x = the i-th member of p[i]
y = the j-th member of p[j]
diff = x - y
better = if(errorMeasures) diff<0 else diff>0
win[i] += better
}
for(i in win)
win[i] = win[i]/(N*samples) * 100 # so now its percents
rank treatments by their position in win (higher rank = more wins)















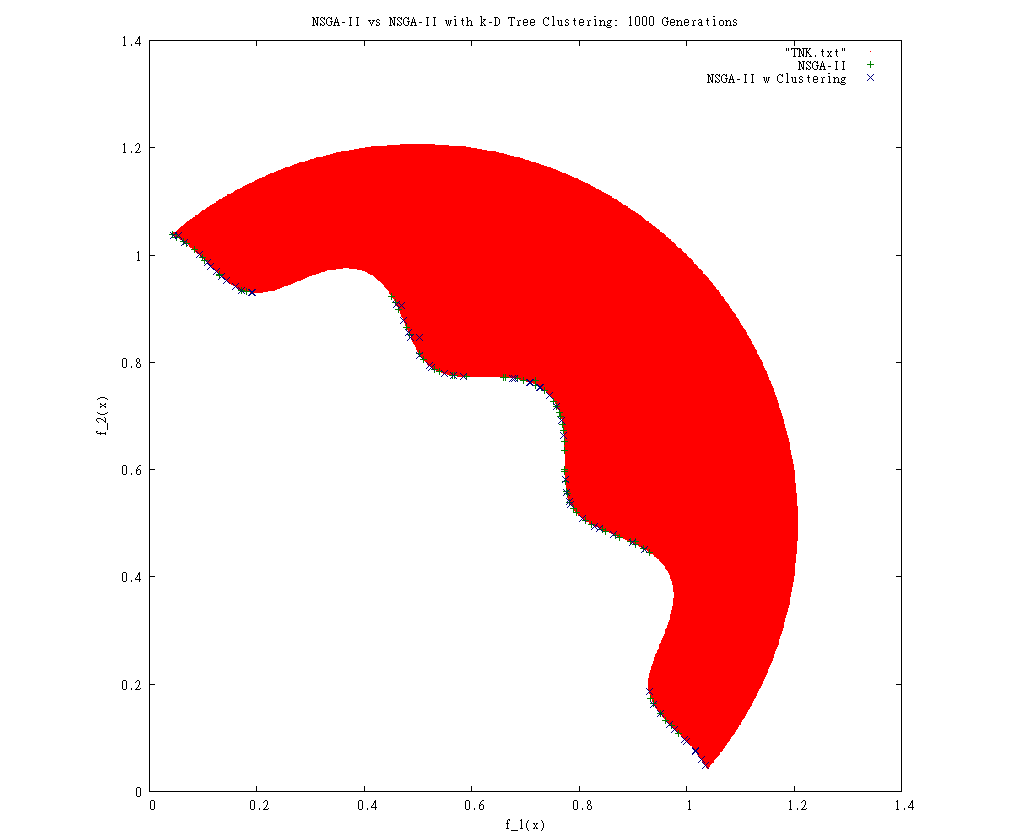





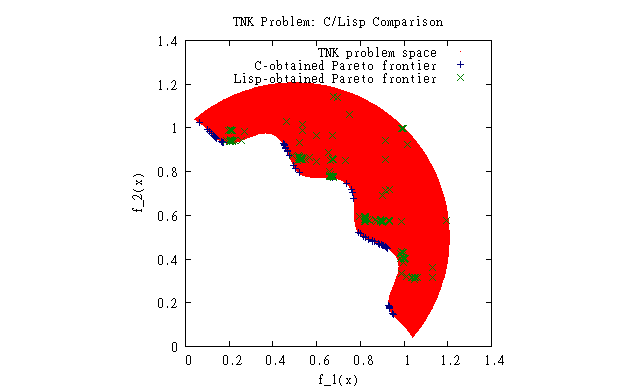 This was the first comparison between the C version and my version. I would have made a new graph, but I somehow lost the C frontier data. I saw that something was very wrong, so I have spent a lot of time trying to fix it. This is as close as I've gotten thus far:
This was the first comparison between the C version and my version. I would have made a new graph, but I somehow lost the C frontier data. I saw that something was very wrong, so I have spent a lot of time trying to fix it. This is as close as I've gotten thus far:












 Left: Regions the agent has explored. Right: The entire dungeon; explored.
Left: Regions the agent has explored. Right: The entire dungeon; explored.







