Monday, September 28, 2009
ICSM 2009 Presentation - Relevance Feedback
Sadly, I couldn't make it to the International Conference on Software Maintenance this year. Fortunately for us, our fantastic contributor Sonia Haiduc could attend and present our paper. She did a great job, and there is a ton of interest in the follow-up work.
The abstract:
Concept location is a critical activity during software evolution as it produces the location where a change is to start in response to a modification request, such as, a bug report or a new feature request. Lexical based concept location techniques rely on matching the text embedded in the source code to queries formulated by the developers. The efficiency of such techniques is strongly dependent on the ability of the developer to write good queries. We propose an approach to augment information retrieval (IR) based concept location via an explicit relevance feedback (RF) mechanism. RF is a two-part process in which the developer judges existing results returned by a search and the IR system uses this information to perform a new search, returning more relevant information to the user. A set of case studies performed on open source software systems reveals the impact of RF on the IR based concept location.
Want to try some treatment learning?
Have a difficult problem to solve? Do you want to know the exact factors that lead to a diagnosis? You might be able to apply treatment learning to the problem.
First, read this and this. Those two articles should give you the basic background. For a more in-depth discussion, take a look at this draft.
If you're feeling brave, go grab the source code for either TAR3 or TAR4.1. NASA has recently given us the newest versions of both treatment learners. To run these, your computer will require a C compiler and the Matlab runtime environment.
TAR Source Code
Warning: This code does have bugs and isn't particularly well-documented. It works, but don't shout at us if it occasionally crashes.
First, read this and this. Those two articles should give you the basic background. For a more in-depth discussion, take a look at this draft.
If you're feeling brave, go grab the source code for either TAR3 or TAR4.1. NASA has recently given us the newest versions of both treatment learners. To run these, your computer will require a C compiler and the Matlab runtime environment.
TAR Source Code
Warning: This code does have bugs and isn't particularly well-documented. It works, but don't shout at us if it occasionally crashes.
Text Mining
Recently, Ourmine was used to perform a large text mining experiment on the following large data sets:
- Express schemas: AP-203, AP-214
- BBC, BBC Sport
- Reuters
- The Guardian, (multi-view text data sets)
- 20 Newsgroup subsets
The main purpose of the experiment was to determine the overall benefits of using slow clustering/dimensionality reduction methods over heuristic means. To conduct the experiment, two dimensionality reduction methods were used - Tf*Idf and PCA - in conjunction with three clustering methods (a naive K-means, GenIc, Canopy clustering).
Tf*Idf, or term frequency * inverse document frequency, is a fast reduction method that reduces the number of attributes in a text data set by filtering out important terms from unimportant ones. The concept here is to identify the terms that appear frequently in a small number of documents, and infrequently across the entire corpus. This allows us to evaluate how "relevant" terms are to that particular document pertaining to a specific concept.
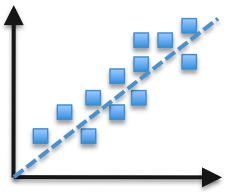
PCA, or Principal Components Analysis, is a reduction method that treats every instance in a dataset as a point in N-dimensional space. PCA looks for new dimensions that better fit these points. In more mathematical terms, it maps possibly correlated variables into a smaller set of uncorrelated variables, which are called principal components. The following image shows an example of how two dimensions can be approximated in a single new dimension feature, as seen by the dashed line.
K-means is a very slow clustering method used (in this experiment) to cluster documents from each corpus. It's a special case of a class of EM algorithms, works as follows:
- Select initial {\em K} centroids at random;
- Assign each incoming point to its nearest centroid;
- Adjusts each cluster's centroid to the mean of each cluster;
- Repeat steps 2 and 3 until the centroids in all clusters stop moving by a noteworthy amount;
GenIc is a single-pass, stochastic (fast) clustering algorithm. It begins by initially selecting K centroids at random from all instances in the data. At the beginning of each generation, set the centroid weight to one. When new instances arrive, nudge the nearest centroid to that instance and increase the score for that centroid. In this process, centroids become "fatter" and slow down the rate at which they move toward newer examples. When a generation ends, replace the centroids with less than X percent of the max weight with N more random centroids. Repeat for many generations and return the highest scoring centroids.Canopy clustering is another heuristic clustering method. Developed by Google, canopy clustering reduces the need for comparing all items in the data using an expensive distance measure, by first partitioning the data into overlapping subsets called "canopies". Canopies are first built using a cheap, approximate distance measure. Then, more expensive distance measures are used inside of each canopy to cluster the data. ResultsIn order to determine the benefit of using each clustering method, cluster purity and similarity are used. When a document's class is given to us, we can determine a cluster's purity by finding how "pure" a cluster is based on the existence of classes per cluster. For instance, if a cluster contains a large number of documents containing a large number of classes, the purity of that cluster is relatively low. However, if a cluster contains a large number of documents with very few classes, we can say that the cluster has a high purity.Cluster similarity tells us how similar documents are either within (intra-cluster similarity) a cluster, or across many clusters (inter-cluster similarity). Thus, we strive for a very high intra-cluster similarity, but a very low inter-cluster similarity based on the concept that clusters are meant to group documents together based on how "similar" they are, therefore we don't want a clustering solution to group documents together that are in no way similar to one another.The results of this experiment are astounding. The following table represents cluster similarities in relation to runtimes normalized to the more rigorous methods (as these were assumed to perform the best).
Reducer and Clusterer Time Intersim Intrasim Gain TF-IDF*K-means 17.52 -0.085 141.73 141.82 TF-IDF*GenIc 3.75 -0.14 141.22 141.36 PCA*K-means 100.0 0.0 100.0 100.0 PCA*Canopy 117.49 0.00 99.87 99.87 PCA*GenIc 11.71 -0.07 99.74 99.81 TF-IDF*Canopy 6.58 5.02 93.42 88.4
In this table, "Gain" is the value of the intra-cluster similarity minus the value of the inter-cluster similarity. Thus, a higher gain represents a better overall score for that particular clusterer and reducer. As can be seen, most methods lie below the more rigorous methods (PCA*K-means). However, TF-IDF produces better results than does PCA on most combinations, and by observing TF-IDF*GenIc, we can see that even though is scores second in the table, its runtime is about 1/5-th that of TF-IDF*K-means.Links to graphs of overall weighted cluster purities are found below for the BBC and BBCSport data sets. As we can see, in BBCSport, slower methods (K-means) provides the highest cluster purity. However, in BBC we can see that GenIc gives us results that are very close to those of slower solutions. BBC purities BBC Sport purities
Sunday, September 27, 2009
New draft: Diagnosis of Mission-Critical Failures
Gregory Gay , Tim Menzies, Misty Davies, Karen Gundy-Burlet
 Testing large-scale systems is expensive in terms of both time and money. Running simulations early in the process is a proven method of finding the design faults likely to lead to critical system failures, but determining the exact cause of those errors is still time-consuming and requires access to a limited number of domain experts. It is desirable to find an automated method that explores the large number of combinations and is able to isolate likely fault points. Treatment learning is a subset of minimal contrast-set learning that, rather than classifying data into distinct categories, focuses on finding the unique factors that lead to a particular classification. That is, they find the smallest change to the data that causes the largest change in the class distribution. These treatments, when imposed, are able to identify the settings most likely to cause a mission-critical failure. This research benchmarks two treatment learning methods against standard optimization techniques across three complex systems, including two pro jects from the Robust Software Engineering (RSE) group within the National Aeronautics and Space Administration (NASA) Ames Research Center. It is shown that these treatment learners are both faster than traditional methods and show demonstrably better results.
Testing large-scale systems is expensive in terms of both time and money. Running simulations early in the process is a proven method of finding the design faults likely to lead to critical system failures, but determining the exact cause of those errors is still time-consuming and requires access to a limited number of domain experts. It is desirable to find an automated method that explores the large number of combinations and is able to isolate likely fault points. Treatment learning is a subset of minimal contrast-set learning that, rather than classifying data into distinct categories, focuses on finding the unique factors that lead to a particular classification. That is, they find the smallest change to the data that causes the largest change in the class distribution. These treatments, when imposed, are able to identify the settings most likely to cause a mission-critical failure. This research benchmarks two treatment learning methods against standard optimization techniques across three complex systems, including two pro jects from the Robust Software Engineering (RSE) group within the National Aeronautics and Space Administration (NASA) Ames Research Center. It is shown that these treatment learners are both faster than traditional methods and show demonstrably better results.
Testing large-scale systems is expensive in terms of both time and money. Running simulations early in the process is a proven method of finding the design faults likely to lead to critical system failures, but determining the exact cause of those errors is still time-consuming and requires access to a limited number of domain experts. It is desirable to find an automated method that explores the large number of combinations and is able to isolate likely fault points. Treatment learning is a subset of minimal contrast-set learning that, rather than classifying data into distinct categories, focuses on finding the unique factors that lead to a particular classification. That is, they find the smallest change to the data that causes the largest change in the class distribution. These treatments, when imposed, are able to identify the settings most likely to cause a mission-critical failure. This research benchmarks two treatment learning methods against standard optimization techniques across three complex systems, including two pro jects from the Robust Software Engineering (RSE) group within the National Aeronautics and Space Administration (NASA) Ames Research Center. It is shown that these treatment learners are both faster than traditional methods and show demonstrably better results.
New draft: Finding Robust Solutions in Requirements Models
Gregory Gay , Tim Menzies , Omid Jalali , Gregory Mundy, Beau Gilkerson, Martin Feather, and James Kiper
Solutions to non-linear requirements engineering problems may be “brittle”; i.e. small changes may dramatically alter solution effectiveness. Therefore, it is not enough to merely generate solutions to requirements problems- we must also assess the robustness of that solution. This paper introduces the KEYS2 algorithm that can generate decision ordering diagrams. Once generated, these diagrams can assess solution robustness in linear time. In experiments with real-world requirements engineering models, we show that KEYS2 can generate decision ordering diagrams in O(N 2 ). When assessed in terms of terms of (a) reducing inference times, (b) increasing solution quality, and (c) decreasing the variance of the generated solution, KEYS2 out-performs other search algorithms (simulated annealing, ASTAR, MaxWalkSat).
Solutions to non-linear requirements engineering problems may be “brittle”; i.e. small changes may dramatically alter solution effectiveness. Therefore, it is not enough to merely generate solutions to requirements problems- we must also assess the robustness of that solution. This paper introduces the KEYS2 algorithm that can generate decision ordering diagrams. Once generated, these diagrams can assess solution robustness in linear time. In experiments with real-world requirements engineering models, we show that KEYS2 can generate decision ordering diagrams in O(N 2 ). When assessed in terms of terms of (a) reducing inference times, (b) increasing solution quality, and (c) decreasing the variance of the generated solution, KEYS2 out-performs other search algorithms (simulated annealing, ASTAR, MaxWalkSat).New draft: Controlling Randomized Unit Testing With Genetic Algorithms
James H. Andrews and Tim Menzies and Felix C. H. Li
Randomized testing is an effective method for testing software units. Thoroughness of randomized unit testing varies widely according to the settings of certain parameters, such as the relative frequencies with which methods are called. In this paper, we describe Nighthawk, a system which uses a genetic algorithm (GA) to find parameters for randomized unit testing that optimize test coverage. Designing GAs is somewhat of a black art. We therefore use a feature subset selection (FSS) tool to assess the size and content of the representations within the GA. Using that tool, we can prune back 90% of our GA’s mutators while still achieving most of the coverage found using all the mutators. Our pruned GA achieves almost the same results as the full system, but in only 10% of the time. These results suggest that FSS for mutator pruning could significantly optimize meta-heuristic search-based software engineering tools.
Randomized testing is an effective method for testing software units. Thoroughness of randomized unit testing varies widely according to the settings of certain parameters, such as the relative frequencies with which methods are called. In this paper, we describe Nighthawk, a system which uses a genetic algorithm (GA) to find parameters for randomized unit testing that optimize test coverage. Designing GAs is somewhat of a black art. We therefore use a feature subset selection (FSS) tool to assess the size and content of the representations within the GA. Using that tool, we can prune back 90% of our GA’s mutators while still achieving most of the coverage found using all the mutators. Our pruned GA achieves almost the same results as the full system, but in only 10% of the time. These results suggest that FSS for mutator pruning could significantly optimize meta-heuristic search-based software engineering tools.Wednesday, September 23, 2009
Great (succinct) list of GnuPlot tricks
http://sparky.rice.edu/gnuplot.html
For example:
For example:
Point size and type
- pointsize is to expand points: set pointsize 2.
- type 'test' to see the colors and point types available
- -1=black
- 1=red
- 2=grn
- 3=blue
- 4=purple
- 5=aqua
- 6=brn
- 7=orange
- 8=light-brn
- 1=diamond
- 2=+
- 3=square
- 4=X
- 5=triangle
- 6=*
(and, for postscipt:
- 1=+,
- 2=X,
- 3=*,
- 4=square,
- 5=filled square,
- 6=circle,
- 7=filled circle,
- 8=triangle,
- 9=filled triangle,
- etc.
Sunday, September 20, 2009
Redefining Classification
HyperPipes is a linear-time dumb-as-a-box-of-hammers data miner that usually scores very badly, except on very spare data sets.
Aaron Riesbeck and Adam Brady added a wriggle to HyperPipes:
So if the task is knowing what it IS, HyperPipes2 may not be useful. But if the task is what it AIN'T, then HyperPipes2 is a useful tool for quickly throw away most of the competing hypotheses.
Aaron Riesbeck and Adam Brady added a wriggle to HyperPipes:
- If N classes score the same, then return all N.
- In this framework "success" means that the real class is within the N.
So if the task is knowing what it IS, HyperPipes2 may not be useful. But if the task is what it AIN'T, then HyperPipes2 is a useful tool for quickly throw away most of the competing hypotheses.
New machines for the AI lab
We are upgrading our machines: six new dual core Dells for the lab and a tower of four dual-cores, just for running data mining experiments.
When the Reviewer is Definitly Wrong
Some of us know the bitter sting of a journal rejection. We've come to curse the existence of "reviewer 2" (really, there's an entire Facebook group devoted to the cause).
Well, sometimes the reviewer is just plain wrong. This paper collects a few reviews from famous academics who, just this once, were completely on the wrong side of history.
My particular favorite? Dijkstra, someone that all of you should be familiar with, wrote a seminal paper warning against the use of goto statements. One reviewer voted to reject it, questioning this notion of structured programming. This reviewer concludes with this gem of a statement:
We all know how this one turned out.
Well, sometimes the reviewer is just plain wrong. This paper collects a few reviews from famous academics who, just this once, were completely on the wrong side of history.
My particular favorite? Dijkstra, someone that all of you should be familiar with, wrote a seminal paper warning against the use of goto statements. One reviewer voted to reject it, questioning this notion of structured programming. This reviewer concludes with this gem of a statement:
Publishing this would waste valuable paper: Should it be published, I am as sure it will go uncited and unnoticed as I am confident that, 30 years from now, the goto will still be alive and well and used as widely as it is today.
The author should withdraw the paper and submit it someplace where it will not be peer reviewed. A letter to the editor would be a perfect choice: Nobody will notice it there!
We all know how this one turned out.
Friday, September 18, 2009
Guide to Writing up Empirical Results
The appendix of this paper offers the headings of standard experimental se paper
I offer this reluctantly since while science may be REPORTED like this, it is not PERFORMED like this. The sentence that really stings is:
Nevertheless, the appendix is a good check list of headings. Feel free to deviate from them but at least it is a place to start
t
I offer this reluctantly since while science may be REPORTED like this, it is not PERFORMED like this. The sentence that really stings is:
- "According to Singer [14], the Analysis section summarizes the data collected and the treatment of the data. The most important points for this section are: (1) It is not allowed to interpret the results [14] and (2) data should be analyzed in accordance with the design [6]. "
Nevertheless, the appendix is a good check list of headings. Feel free to deviate from them but at least it is a place to start
t
Monday, September 14, 2009
Zachary Murray
 Zachary Murray is an undergraduate research assistant with the Modeling Intelligence Lab at WVU. He is currently studying Computer Science with a minor in Mathematics and expects to graduate in May 2010.
Zachary Murray is an undergraduate research assistant with the Modeling Intelligence Lab at WVU. He is currently studying Computer Science with a minor in Mathematics and expects to graduate in May 2010.Zack assists the graduate students by providing critical programming support and interface design for the MIL's latest and greatest projects.
Sunday, September 13, 2009
Trusting Effort Estimation Results
Standard estimators for software development effort offer one number: the prediction.
It would be nice to know how much (if at all) we can trust that prediction. To this end, Ekrem Kocagüneli at Softlab (in Turkey) applied Greedy Agglomerative Clustering to generate a binary tree whose leaves are real training instances and whose internal nodes are a mid-way point between their two children. He found a relationship between prediction error and variance of the performance statistic (*) in the sub-tree. That is, we can return not just the estimate, but an trust measure of how much we should believe that estimate.
(* Ekrem build predictions via the median of the estimate in the leaves of the subtree).
In the following experiments, 20 times, we took out one training instance, GAC the remaining, then estimated the set-aside. Note that after some critical value of variance (on the x-axis), the error spikes (on the y-axis). So, if your test instance falls into sub-trees with that variance, do not trust the estimate
In the following diagram:

For more details, see here.
It would be nice to know how much (if at all) we can trust that prediction. To this end, Ekrem Kocagüneli at Softlab (in Turkey) applied Greedy Agglomerative Clustering to generate a binary tree whose leaves are real training instances and whose internal nodes are a mid-way point between their two children. He found a relationship between prediction error and variance of the performance statistic (*) in the sub-tree. That is, we can return not just the estimate, but an trust measure of how much we should believe that estimate.
(* Ekrem build predictions via the median of the estimate in the leaves of the subtree).
In the following experiments, 20 times, we took out one training instance, GAC the remaining, then estimated the set-aside. Note that after some critical value of variance (on the x-axis), the error spikes (on the y-axis). So, if your test instance falls into sub-trees with that variance, do not trust the estimate
In the following diagram:
- x-axis: weighted variance of sub-tree
- y-axis: log of error = magnitude of relative error = abs(actual - predicted)/ actual
For more details, see here.
Case-based Software Engineering

The Wednesday group that does teleconferences with Australia has a new web site.
It contains a list of interesting readings on case-based CBR. In particular, there is a video on CBR for gaming.
Apology to Turing
Alan Turing, a gay computer genius who was instrumental in World War II, received a posthumous apology from Prime Minister Gordon Brown for the state's persecution of Turing's homosexuality.
Turing's efforts in the war uncovered German military secrets and, according to BBC, shortened the war by two years.
Tried and convicted of homosexuality, he opted for chemical castration, a series of injected female hormones, rather than imprisonment. Two years later, he committed suicide.
After thousands had signed a petition for the government to apologize, Mr. Brown did so through an article in the Daily Telegraph.
Mr. Brown writes, “I am pleased to have the chance to say how deeply sorry I and we all are for happened to him. Alan and the many thousands of other gay men who were convicted as he was convicted, under homophobic laws, were treated terribly.”
[more]
Turing's efforts in the war uncovered German military secrets and, according to BBC, shortened the war by two years.
Tried and convicted of homosexuality, he opted for chemical castration, a series of injected female hormones, rather than imprisonment. Two years later, he committed suicide.
After thousands had signed a petition for the government to apologize, Mr. Brown did so through an article in the Daily Telegraph.
Mr. Brown writes, “I am pleased to have the chance to say how deeply sorry I and we all are for happened to him. Alan and the many thousands of other gay men who were convicted as he was convicted, under homophobic laws, were treated terribly.”
[more]
Quicker Quicksort
A lot of we do requires sorting. For years, the best-of-breed was quicksort, perhaps with a randomizer pre-processor to avoid the worst-case scenario of already sorted data. BTW, here is a linear-time randomiser:
function nshuffle(a, i,j,n,tmp) {
n=a[0]; # a has items at 1...n
for(i=1;i<=n;i++) {
j=i+round(rand()*(n-i));
tmp=a[j];
a[j]=a[i];
a[i]=tmp;
};
return n;
}
function round(x) { return int(x + 0.5) }
Now there is empirical evidence that a new quicksort that uses two (not one) pivots is faster:
- Pick an elements P1, P2, called pivots from the array.
- Assume that P1 <= P2, otherwise swap it.
- Reorder the array into three parts: those less than the smaller
pivot, those larger than the larger pivot, and in between are
those elements between (or equal to) the two pivots. - Recursively sort the sub-arrays.
Monday, September 7, 2009
Todos: 09/08/2009
From the meeting invitation:
- zach : looking forward to an interface where i can enter meta-info on each of the features
- fayola: is your clusterer still broken?
- bryan: is running a temperature and if that persists, he plans to stay away.
- Greg: text mining experiment, bug Misty for paper edits, ASE paper, Promise stuff
KEYS and KEYS2

Within a model, there are chains of reasons that link inputs to the desired goals. As one might imagine, some of the links in the chain clash with others. Some of those clashes are most upstream; they are not dependent on other clashes. In the following chains of reasoning, the clashes are {e, -e}, {g, -g}, {j, -j}; the most upstream clashes are {e, -e}, {g, -g}

In order to optimize decision making about this model, we must first decide about these most upstream clashing reasons (the "keys"). Most of this model is completely irrelevant. In the context of reaching the goal, the only important discussions are the clashes {g,-g,j, -j}. Further, since {j, -j} are dependent on {g, -g}, then the core decision must be about variable g with two disputed values: true and false.
Setting the keys reduces the number of reachable states within the model. Formally, the reachable states reduce to the cross-product of all of the ranges of the collars. We call this the clumping effect. Only a small fraction of the possible states are actually reachable. This notion of $keys$ has been discovered and rediscovered
many times by many researchers. Historically, finding the keys has seen to be a very hard task. For example, finding the keys is analogous to finding the minimal environments of DeKleer's ATMS algorithm. Formally, this is logical abduction, which is an NP-hard task.
Our method for finding the keys uses a Bayesian sampling method. If a model contains keys then, by definition, those variables must appear in all solutions to that model. If model outputs are scored by some oracle, then the key variables are those with ranges that occur with very different frequencies in high/low scored model outputs. Therefore, we need not search for the keys- rather, we just need to keep frequency counts on how often ranges appear in best or rest outputs.
KEYS implements this Bayesian sampling methods. It has two main components - a greedy search and the BORE ranking heuristic. The greedy search explores a space of M mitigations over the course of M "eras". Initially, the entire set of mitigations is set randomly. During each era, one more mitigation is set to M_i=X_j, X_j being either true or false. In the original version of KEYS, the greedy search fixes one variable per era. Recent experiments use a newer version, called KEYS2, that fixes an increasing number of variables as the search progresses
(see below for details).
KEYS (and KEYS2), each era e generates a set
- [1:] MaxTries times repeat:
- Selected[1{\ldots}(e-1)] are settings from previous eras.
- Guessed are randomly selected values for unfixed mitigations.
- Input = selected from guessed.
- Call model to compute score=ddp(input);
- Selected[1{\ldots}(e-1)] are settings from previous eras.
- [2:] The MaxTries scores are divided into B "best" and the remainder become the "rest".
- [3:] The input mitigation values are then scored using BORE (described below).
- [4:] The top ranked mitigations (the default is one, but the user may fix multiple mitigations at once) are fixed and stored in selected[e].
The search moves to era e+1 and repeats steps 1,2,3,4. This process stops when every mitigation has a setting. The exact settings for MaxTries and B must be set via engineering judgment. After some experimentation, we used MaxTries=100 and B=10.
Pseudocode for the KEYS algorithm:
1. Procedure KEYS
2. while FIXED_MITIGATIONS != TOTAL_MITIGATIONS
3. for I:=1 to 100
4. SELECTED[1...(I-1)] = best decisions up to this step
5. GUESSED = random settings to the remaining mitigations
6. INPUT = SELECTED + GUESSED
7. SCORES= SCORE(INPUT)
8. end for
9. for J:=1 to NUM_MITIGATIONS_TO_SET
10. TOP_MITIGATION = BORE(SCORES)
11. SELECTED[FIXED_MITIGATIONS++] = TOP_MITIGATION
12. end for
13. end while
14. return SELECTED \end{verbatim} }
KEYS ranks mitigations by combining a novel support-based Bayesian ranking measure. BORE (short for "best or rest") divides numeric scores seen over K runs and stores the top 10% in best and the remaining 90% scores in the set rest (the bes$ set is computed by studying the delta of each score to the best score seen in any era). It then computes the probability that a value is found in best using Bayes theorem. The theorem uses evidence E and a prior probability P(H) for hypothesis H in{best, rest}, to calculate a posterior probability

When applying the theorem, likelihoods are computed from observed frequencies. These likelihoods (called "like" below) are then normalized to create probabilities. This normalization cancels out P(E) in Bayes theorem. For example, after K=10,000 runs are divided into 1,000 best solutions and 9,000 rest, the value mitigation31=false might appear 10 times in the best solutions, but only 5 times in the rest. Hence:

Previously, we have found that Bayes theorem is a poor ranking heuristic since it is easily distracted by low frequency evidence. For example, note how the probability of E belonging to the best class is moderately high even though its support is very low; i.e. P(best|E)=0.66 but freq(E|best) = 0.01.
To avoid the problem of unreliable low frequency evidence, we augment the equation with a support term. Support should increase as the frequency of a value increases, i.e. like(best|E) is a valid support measure. Hence, step 3 of our greedy search ranks values via

For each era, KEYS samples the model and fixes the top N=1 settings. Observations have suggested that N=1 is, perhaps, an overly conservative search policy. At least for the DDP models, we have observed that the improvement in costs and attainments generally increase for each era of KEYS. This lead to the speculation that we could jump further and faster into the solution space by fixing N=1 settings per era. Such a jump policy can be implemented as a small change to KEYS, which we call KEYS2.
- Standard KEYS assigns the value of one to NUM_MITIGATIONS_TO_SET (see the pseudocode above);
- Other variants of KEYS assigns larger values.
In era 1, KEYS2 behaves exactly the same as KEYS. In (say) era 3, KEYS2 will fix the top 3 ranked ranges. Since it sets more variables at each era, KEYS2 terminates earlier than KEYS.
TAR4.1
New to Treatment Learning and TAR3? Read this first.
TAR3 is not a data miner. Not only does it have a different goal (treatment versus classification), its very design runs counter to that of traditional classifiers such as Naive Bayes. Data miners, according to Bradley et al:
Require one scan, or less, of the data.
Are on-line, anytime algorithms.
Are suspendable, stoppable, and resumable.
Efficiently and incrementally add new data to existing models.
Work within the available RAM.
TAR3 stores all examples from the dataset in RAM. It also requires three scans of the data in order to discretize, build theories, and rank the generated treatments. TAR4 was designed and modeled after the SAWTOOTH incremental Naive Bayes classifier in order to improve the runtime, lessen the memory usage, and better scale to large datasets.
Pseudocode framework for a treatment learner. TAR3 and TAR4.1 use this basic framework, each defining their own objective function:
Naive Bayes classifiers offer a relationship between fragments of evidence E_i, a prior probability for a class P(H), and a posterior probability P(H|E):
For numeric features, a features mean and standard deviation are used in a Gaussian probability function:

Simple naive Bayes classifiers are called "naive" since they assume independence of each feature. Potentially, this is a significant problem for data sets where the static code measures are highly correlated (e.g. the number of symbols in a module increases linearly with the module's lines of code). However, Domingos and Pazzini have shown theoretically that the independence assumption is a problem in a vanishingly small percent of cases.
TAR4.1 still requires two passes through the data, for discretization and for building treatments. These two steps function in exactly the same manner as the corresponding steps in the TAR3 learner. TAR4.1, however, eliminates the final pass by building a scoring cache during the BORE classification stage. During classification, examples are placed in a U-dimensional hypercube, with one dimension for each utility. Each example e in E has a normalized distance 0 <= D_i <= 1 from the apex, the area where the best examples reside. When BORE classifies examples into best and rest, that normalized distance adds D_i to the down table and 1-D_i to the up table.
When treatments are scored by TAR4.1, the algorithm does a linear-time table lookup instead of scanning the entire dataset. Each range R_j containing example_i adds down_i and up_i to frequency counts F(R_j|base) and F(R_j|apex). These frequency counts
are then used to compute the following equations:

TAR4.1 finds the smallest treatment T that maximizes:

Note the squared term in the top of the equation, L(apex|T)^2. This term was not squared in the first design of TAR4. The first version of TAR4 was a failure. Its results were muddled by the dependent attributes. The standard Naive Bayes assumes independence between all attributes and keeps singleton counts. TAR4 added redundant information, which altered the probabilities. In effect, it produced treatments with high scores, but without the minimum best support required in TAR3. TAR4.1 was redesigned to prune treatments with low support in the original dataset. By squaring the likelihood that a range appears in the apex, those treatments that lack support are dropped in favor of those that appear often in the apex.
TAR3 is not a data miner. Not only does it have a different goal (treatment versus classification), its very design runs counter to that of traditional classifiers such as Naive Bayes. Data miners, according to Bradley et al:
TAR3 stores all examples from the dataset in RAM. It also requires three scans of the data in order to discretize, build theories, and rank the generated treatments. TAR4 was designed and modeled after the SAWTOOTH incremental Naive Bayes classifier in order to improve the runtime, lessen the memory usage, and better scale to large datasets.
Pseudocode framework for a treatment learner. TAR3 and TAR4.1 use this basic framework, each defining their own objective function:
1. Procedure TreatmentLearner(LIVES=MAX_LIVES)
2. for every range R
3. SCORES[R]:=score(R)
4. while LIVES>0
5. BEFORE:= size(TEMP)
6. TEMP:= union(TEMP,some())
7. if BEFORE:= size(TEMP)
8. LIVES--
9. else
10. LIVES:= MAX_LIVES
11. sort(TEMP) by score()
12. return TOP_ITEMS
1. Procedure one(X=random(SIZE))
2. for 1 to X
3. TREATMENT:=TREATMENT+ a random range from CDF(SCORES)
4. return TREATMENT
1. Procedure some
2. for 1 to REPEATS
3. TREATMENTS:= TREATMENTS + one()
4. sort(TREATMENTS) by score()
5. return TOP_ITEMS
Naive Bayes classifiers offer a relationship between fragments of evidence E_i, a prior probability for a class P(H), and a posterior probability P(H|E):
For numeric features, a features mean and standard deviation are used in a Gaussian probability function:
Simple naive Bayes classifiers are called "naive" since they assume independence of each feature. Potentially, this is a significant problem for data sets where the static code measures are highly correlated (e.g. the number of symbols in a module increases linearly with the module's lines of code). However, Domingos and Pazzini have shown theoretically that the independence assumption is a problem in a vanishingly small percent of cases.
TAR4.1 still requires two passes through the data, for discretization and for building treatments. These two steps function in exactly the same manner as the corresponding steps in the TAR3 learner. TAR4.1, however, eliminates the final pass by building a scoring cache during the BORE classification stage. During classification, examples are placed in a U-dimensional hypercube, with one dimension for each utility. Each example e in E has a normalized distance 0 <= D_i <= 1 from the apex, the area where the best examples reside. When BORE classifies examples into best and rest, that normalized distance adds D_i to the down table and 1-D_i to the up table.
When treatments are scored by TAR4.1, the algorithm does a linear-time table lookup instead of scanning the entire dataset. Each range R_j containing example_i adds down_i and up_i to frequency counts F(R_j|base) and F(R_j|apex). These frequency counts
are then used to compute the following equations:
TAR4.1 finds the smallest treatment T that maximizes:
Note the squared term in the top of the equation, L(apex|T)^2. This term was not squared in the first design of TAR4. The first version of TAR4 was a failure. Its results were muddled by the dependent attributes. The standard Naive Bayes assumes independence between all attributes and keeps singleton counts. TAR4 added redundant information, which altered the probabilities. In effect, it produced treatments with high scores, but without the minimum best support required in TAR3. TAR4.1 was redesigned to prune treatments with low support in the original dataset. By squaring the likelihood that a range appears in the apex, those treatments that lack support are dropped in favor of those that appear often in the apex.
Ourmine

Ourmine is a data mining toolkit built to be easily learned/taught. It implements a variety of languages constructed in a modular way, providing the opportunity for easy extendability.
Ourmine features
- Easily obtained and can be run from any UNIX based operating system, including OSX & Linux
- Without the complications of a GUI, advanced data mining concepts can be taught effectively through the use of just a few commands
- Ourmine utilizes a modulated structure, allowing experiments to be easily conducted using Ourmine by adding any custom code
- Along with its many data preparation and formatting functions, Ourmine allows the power of interactive bash scripting to be conducted on the fly, providing a higher level of understanding and productivity
- And much more...
For more information about Ourmine, please go here
Thursday, September 3, 2009
Fayola Peters

Fayola's journey into the world of Computer Science began in 2004 as an undergrad at Coppin State University in Baltimore.
Currently, she is working toward her Master's degree at West Virginia University and has jumped onto the Forensic Interpretation Model research path.
CLIFF

CLIFF is a plotting tool which offers the visualization of data. This software features four(4) of the current models used in the forensic community, namely the 1995 Evett model, the 1996 Walsh model, the Seheult model and the Grove model. For each model, data can be generated randomly and plotted. Other features of CLIFF include:
- the ability to perform dimensionality reduction by applying the Fastmap algorithm
- the ability to determine if the results gained from a region of space is important and well supported.
Tuesday, September 1, 2009
TAR3

Testing large-scale systems is expensive in terms of both time and money. Running simulations early in the process is a proven method of finding the design faults likely to lead to critical system failures, but determining the exact cause of those errors is still a time-consuming process and requires access to a limited number of domain experts. It is desirable to find an automated method that explores the large number of combinations and is able to isolate likely fault points.
Treatment learning is a subset of minimal contrast-set learning that, rather than classifying data into distinct categories, focuses on finding the unique factors that lead to a particular classification. That is, they find the smallest change to the data that causes the largest change in the class distribution. These treatments, when imposed, are able to identify the settings most likely to cause a mission-critical failure.
Pseudocode framework for a treatment learner. TAR3 and TAR4.1 use this basic framework, each defining their own objective function:
1. Procedure TreatmentLearner(LIVES=MAX_LIVES)
2. for every range R
3. SCORES[R]:=score(R)
4. while LIVES>0
5. BEFORE:= size(TEMP)
6. TEMP:= union(TEMP,some())
7. if BEFORE:= size(TEMP)
8. LIVES--
9. else
10. LIVES:= MAX_LIVES
11. sort(TEMP) by score()
12. return TOP_ITEMS
1. Procedure one(X=random(SIZE))
2. for 1 to X
3. TREATMENT:=TREATMENT+ a random range from CDF(SCORES)
4. return TREATMENT
1. Procedure some
2. for 1 to REPEATS
3. TREATMENTS:= TREATMENTS + one()
4. sort(TREATMENTS) by score()
5. return TOP_ITEMS
TAR3 (and its predecessor TAR2) are based on two fundamental concepts - lift and support.
The lift of a treatment is the change that some decision makes to a set of examples after imposing that decision. TAR3 is given a set of training examples E. Each example in E maps a set of attribute ranges R_i, R_j, ... -> C to some class score. The class symbols C_1, C_2,... are stamped with a rank generated from a utility score {U_1 < U_2 < ... < U_C}. Within E, these classes occur at frequencies F_1, F_2,..., F_C where sum(F_i) = 1. A treatment T of size M is a conjunction of attribute ranges {R_1 ^ R_2... ^ R_M}. Some subset of e from E is contained within the treatment. In that subset, the classes occur at frequencies f_1, f_2,..., f_C. TAR3 seeks the smallest treatment T which induces the biggest changes in the weighted sum of the utilities times frequencies of the classes. Formally, the lift is defined as:
lift = sum(U_c*f_c)/sum(U_c*F_c)
The classes used for treatment learning get a score U_C and the learner uses this to assess the class frequencies resulting from applying a treatment, finding the subset of the inputs that falls within the reduced treatment space. In normal operation, a treatment learner conducts controller learning; that is, it finds a treatment which selects for better classes and rejects worse classes. By reversing the scoring function, treatment learning can also select for the worst classes and reject the better classes. This mode is called monitor learning because it locates the one thing we should most watch for.
Real-world datasets, especially those from hardware systems, contain some noise, incorrect or misleading data caused my accidents and miscalculations. If these noisy examples are perfectly correlated with failing examples, the treatment may become overfitted. An overfitted model may come with a massive lift score, but it does not
accurately reflect the details of the entire dataset. To avoid overfitting, learners need to adopt a threshold and reject all treatments that fall on the wrong side of this threshold. We define this threshold as the minimum best support.
Given the desired class, the best support is the ratio of the frequency of that class within the treatment subset to the frequency of that class in the overall dataset. To avoid overfitting, TAR3 rejects all treatments with best support lower than a user-defined minimum (usually 0.2). As a result, the only treatments returned by TAR3 will have both a high lift and a high best support. This is also the reason that TAR3 prefers smaller treatments. The fewer rules adopted, the more evidence that will exist supporting those rules.
TAR3's lift and support calculations can assess the effectiveness of a treatment, but they are not what generates the treatments themselves. A naive treatment learner might attempt to test all subsets of all ranges of all of the attributes. Because a dataset of size N has 2^N possible subsets, this type of brute force attempt is inefficient. The art of a good treatment learner is in finding good heuristics for generating
candidate treatments.
The algorithm begins by discretizing every continuous attribute into smaller ranges by sorting their values and dividing them into a set of equally-sized bins. It then assumes the small-treatment effect; that is, it only builds treatments up to a user-defined size. Past research has shown that treatments size should be less than four attributes. TAR3 will then only build treatments from the discretized ranges with
a high heuristic value.

TAR3 determines which ranges to use by first determining the lift of each individual attribute. These individual scores are then sorted and converted into a cumulative probability distribution. TAR3 randomly selects values from this distribution, meaning that low-scoring ranges are unlikely to be selected. To build a treatment, n (random from 1...max treatment size) ranges are selected and combined. These treatments are then scored and sorted. If no improvement is seen after a certain number of rounds, TAR3 terminates and returns the top treatments.
Subscribe to:
Comments (Atom)